I burned through my Claude credits in two days the first time I used Claude Code seriously. No warning, no gradual slowdown, just a hard stop. That experience sent me down a deep research rabbit hole that changed how I use Claude Code and Cowork permanently.
The good news is that saving credits is not about doing less. It is about doing the same work smarter. I have cut my Claude token usage by over 60% without reducing output quality, and in this guide I am sharing every technique I use, including ones I found buried in the official Anthropic docs that most guides skip entirely.
Key Takeaways
Why Claude Credits Disappear Faster Than You Expect
Before I get into the fixes, I want to explain the mechanic that causes most waste. Every message you send forces Claude to re-read your entire conversation from scratch. Every single turn. That means a 50-turn conversation costs 50x more in input tokens than a single-turn conversation, even if the actual task is small.
On top of that, Claude Code automatically loads your CLAUDE.md file, all active MCP server tool definitions, your project skills, and system context before your first message. On a bloated setup, you could be spending 20,000-40,000 tokens just on session startup, before you ask Claude to do anything at all.
This is not Claude being inefficient. It is the fundamental cost of how large language models work. Understanding this changes how you structure everything.
1. Master /clear and /compact : The Two Commands That Save the Most Credits

I use these two commands more than almost any other feature in Claude Code. They are the fastest, most immediate way to stop token waste.
/clear : Start fresh, save everything
/clear wipes the entire conversation history. After running it, only your CLAUDE.md and session configuration reload. The context window is empty.
Use /clear every time you switch to a completely different task. I run it religiously between projects, between unrelated features, and after any long debugging session. The tokens you save by not dragging 40 turns of context into a new task are significant.
One tip I picked up from the official docs: run /rename before you clear, so you can find and /resume the session later if you need to reference it.
/compact : Summarize without losing the thread
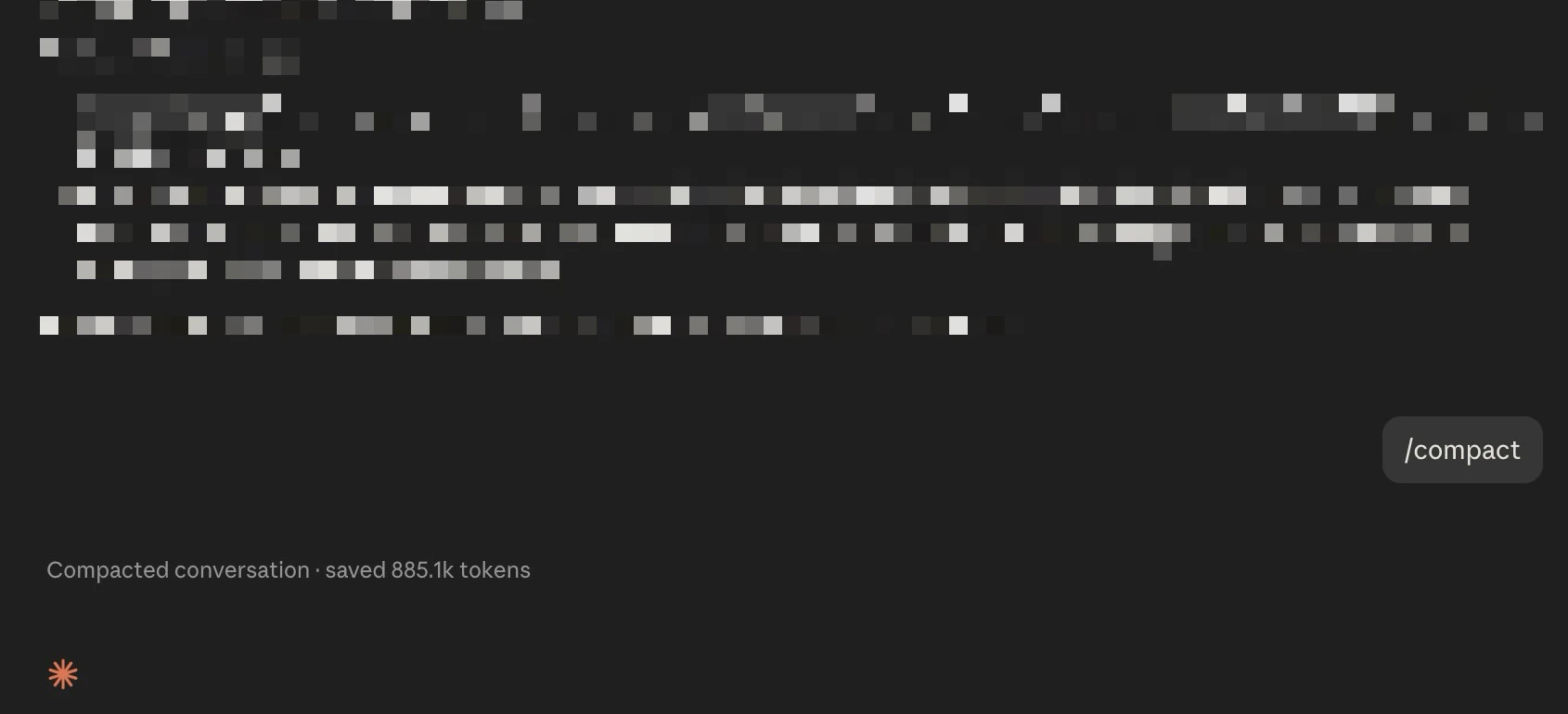
/compact replaces your conversation history with a compressed summary. You keep a record of what was discussed, but the raw token cost of that history is dramatically reduced.
Use /compact when you are mid-task and the session is getting long but you still need continuity. The official recommendation from Anthropic is to run /compact at around 60% context usage, not 90%. If you wait until 90%, the compaction itself costs more and the summary is less precise.
You can also add custom compaction instructions to tell Claude what to preserve:
/compact Focus on code samples, file paths, and the current task only
Or set it permanently in your CLAUDE.md:
# Compact instructions When compacting, prioritize: current task state, file changes, test results. Drop: exploratory conversations, resolved errors, tangential discussions.
I added this to my CLAUDE.md six months ago and it has noticeably improved the quality of my compacted summaries.
2. Keep CLAUDE.md Under 200 Lines (Official Anthropic Recommendation)

This is one of the most specific and actionable recommendations in Anthropic's official documentation, and I see most users ignoring it completely.
Your CLAUDE.md file loads into context at the start of every session. It is there before your first message. Every line in it costs tokens on every turn. A 600-line CLAUDE.md does not just cost more at startup, it compounds across every message in the session.
The right content for CLAUDE.md is essentials only:
The wrong content for CLAUDE.md is anything task-specific, workflow-specific, or situational. Those belong in Skills, which I cover next.
My personal CLAUDE.md sits at 87 lines. When I am tempted to add something, I ask: "Is this needed for every single session, or just specific workflows?" If the answer is "specific workflows," it goes into a skill instead.
3. Move Specialized Instructions Into Skills (Load On-Demand, Not Always)

Skills are one of the most underutilized credit-saving features in both Claude Code and Cowork. Unlike CLAUDE.md, a skill only loads when Claude invokes it. If you are not doing a PR review, your PR review instructions consume zero tokens.
The workflow I follow:
For PR reviews, invoke the /review skillThe result: my base session context dropped by about 35% just from this migration. Skills load in seconds and the quality of the output is identical, often better, because the full skill instructions come in clean instead of buried in a long CLAUDE.md.
In Cowork, skills work the same way. Each installed skill adds overhead only when invoked. Keeping your active plugin set lean has a direct credit impact.
4. Disable MCP Servers You Are Not Using

This one surprised me when I first measured it. A single MCP server with many tools can consume thousands of tokens in tool definitions before you do any work.
One developer shared that their mcp-omnisearch server alone consumed 14,214 tokens per session, just from its 20 tool definitions being listed. Multiply that across 5-6 active MCP servers and you are looking at 50,000-80,000 tokens of overhead on every session start.
The fix is straightforward:
Run /mcp in Claude Code to see all active servers. Disable anything you are not actively using for the current task. Re-enable servers when you need them.
The official Anthropic documentation makes a specific preference clear: use CLI tools over MCP servers when both options exist. Tools like gh, aws, gcloud, and sentry-cli are more context-efficient than their MCP server equivalents because they add zero per-tool listing overhead. Claude can call CLI tools directly without any token cost at session start.
In Cowork, the same principle applies to plugins. Every connected plugin with active MCP tools adds to your session context. I review my active plugin connections monthly and disconnect anything I have not used in two weeks.
5. Choose the Right Model for Each Task

Not every task needs Opus. This is one of the most direct ways to save credits, and it is a habit I had to consciously build because the temptation to always use the most capable model is real.
Here is my model selection framework:
Use Haiku for: Simple rewrites, generating boilerplate, formatting data, answering straightforward questions, quick file reads, subagent coordination tasks.
Use Sonnet for: Most coding tasks, content creation, research, analysis, outlines, debugging, and anything that is not genuinely complex. Sonnet handles 85% of my work and costs significantly less than Opus.
Use Opus for: Architectural decisions, complex multi-file refactoring, deep analysis across a large codebase, anything that genuinely requires advanced reasoning over many competing constraints.
Switch models mid-session with /model. Set a session default in /config. For subagents, the official Anthropic docs explicitly recommend specifying model: haiku in your subagent configuration for routine coordination tasks, this alone can reduce agent team costs substantially.
6. Control Extended Thinking : It Is Billing You as Output Tokens

Extended thinking is enabled by default in Claude Code. It is powerful, but it is also expensive. Thinking tokens bill as output tokens, and the default budget can reach tens of thousands of tokens per request on complex models.
For simple or well-defined tasks, this is pure waste.
Three ways I control it:
Lower the effort level for simple tasks:
/effort low
This reduces the thinking budget without disabling the feature.
Cap the global budget with an environment variable:
MAX_THINKING_TOKENS=8000
I set this in my environment for projects where tasks are mostly routine. If I hit a complex task, I temporarily raise it.
Disable thinking entirely for a session: Open /config and toggle thinking off. I do this for sessions focused on writing, formatting, or other tasks that do not benefit from deep reasoning.
The official Anthropic guidance is clear: extended thinking significantly improves performance on complex planning tasks, but for simpler tasks it is unnecessary cost. Match the tool to the task.
7. Use Subagents for Verbose Operations
This is one of the most powerful but least-understood token-saving techniques.
When Claude processes a 10,000-line log file, runs a full test suite, or fetches and reads large documentation pages, all of that output lands in your main conversation context. It costs tokens on every subsequent message in the session, not just the message where it happened.
Subagents solve this. When you delegate a verbose operation to a subagent, that heavy output stays inside the subagent's isolated context window. Only the summary returns to your main conversation. Your main context stays clean.
Practical use cases where I delegate to subagents:
The official Anthropic documentation puts it simply:
"Delegate verbose operations to subagents so the verbose output stays in the subagent's context while only a summary returns to your main conversation."
Agent teams are the full expression of this pattern, but the official docs warn that agent teams use approximately 7x more tokens than standard sessions when teammates run in plan mode. Keep agent teams small, keep tasks focused, and clean up teams when work is done. Active teammates consume tokens even when idle.
8. Use Hooks to Preprocess Data Before Claude Sees It
![members.promptslove.com [SSH root@144.217.67.21622] — SKILL.md.jgaODKPc.jpg](/api/uploads/50027e84-2558-4341-93b8-63e7d0950fe3.webp)
Hooks are Claude Code's event interception system. They run before and after Claude's tool calls, and they can dramatically reduce what Claude actually has to process.
The example I use most: test output filtering.
Without a hook, running npm test returns hundreds of lines, successful tests, coverage reports, timestamps, file paths. I only care about failures. With a PreToolUse hook that filters test commands to show only failures, I went from 3,000-token test outputs to 80-token summaries.
Here is the hook pattern from the official Anthropic docs:
#!/bin/bash
input=$(cat)
cmd=$(echo "$input" | jq -r '.tool_input.command')
if [[ "$cmd" =~ ^(npm test|pytest|go test) ]]; then
filtered_cmd="$cmd 2>&1 | grep -A 5 -E '(FAIL|ERROR|error:)' | head -100"
echo "{\"hookSpecificOutput\":{\"hookEventName\":\"PreToolUse\",\"permissionDecision\":\"allow\",\"updatedInput\":{\"command\":\"$filtered_cmd\"}}}"
else
echo "{}"
fiBeyond test filtering, I use hooks for:
Each hook that preprocesses data before Claude reads it is a direct token saving. The logic runs locally for free; the token cost of what Claude actually processes drops significantly.
9. Create a .claudeignore File for Large Projects
Claude Code respects a .claudeignore file that works exactly like .gitignore. Files and directories you list there are invisible to Claude, it cannot read them, search them, or accidentally load them during exploration.
For projects with hundreds of files, this is essential. Without it, Claude can spend tokens reading node_modules, build output, generated files, vendor directories, and other irrelevant content during code exploration.
Where to add it?
~/.claude/.claudeignore
My standard .claudeignore template:
node_modules/ dist/ build/ .next/ vendor/ *.lock *.log coverage/ .env __pycache__/ *.pyc
This file costs nothing to maintain and prevents entire categories of unnecessary file reads. On a project with 2,000 files where 1,500 are node_modules or build output, the token savings from a .claudeignore are substantial.
10. Write Specific, Scoped Prompts : Vague Requests Are Expensive
This is the habit that separates efficient Claude Code users from expensive ones. Vague requests trigger broad scanning. Specific requests let Claude work efficiently with minimal file reads.
The contrast is clear:
Expensive prompt: "Improve this codebase" Claude reads dozens of files trying to understand what "improve" means, generates broad suggestions, explores the full directory tree. You spend thousands of tokens on exploration before any work happens.
Efficient prompt: "Add input validation to the login function in src/auth/login.ts. Validate that email is a valid email format and password is at least 8 characters. Return a 400 error with a specific message for each validation failure." Claude reads one file, makes the change, done.
Two additional habits that save credits on complex tasks:
Use plan mode before implementation. Press Shift+Tab to enter plan mode. Claude explores the codebase and proposes an approach for your approval. If the plan is wrong, you correct it before any code is written. Without plan mode, Claude can go deep down the wrong path, spending tokens on work you will discard.
Press Escape early. If Claude starts heading the wrong direction mid-task, stop it immediately with Escape. Use /rewind to restore conversation and code to a checkpoint. Letting a wrong approach run to completion and then asking for corrections costs 2-3x more tokens than catching it early.
11. Track Your Usage and Set Limits

You cannot optimize what you do not measure. The /usage command in Claude Code shows your current session token consumption broken down by type. I run it regularly during long sessions to check where I am in the context window before it hits auto-compaction territory.
For API users: set workspace spend limits in the Claude Console to prevent surprise bills. Under your workspace settings, you can cap total monthly spend and receive alerts at thresholds you define.
For teams: the official Anthropic rate limit recommendations scale by team size. A solo developer should request 200k-300k TPM. A 20-person team needs roughly 50k-75k TPM per user. Allocating correctly prevents both over-spending and hitting rate limits during peak usage.
For Cowork users on subscription plans: the dollar estimate in /usage does not reflect your billing directly, but the token counts are real. High token sessions burn through your included usage faster. The same optimization techniques apply, they just affect how many tasks you can complete within your plan rather than how much your bill is.
12. Use the Batch API for Non-Urgent Work (50% Discount)
This one is specifically for API users, but it is significant enough to include.
Claude's Batch API offers a 50% discount on both input and output tokens for work that does not need to be completed instantly. The trade-off is a 24-hour turnaround time.
Use cases where I route work to the Batch API:
For interactive work, real-time API is necessary. For background jobs and non-urgent generation tasks, batching half the input and output cost is one of the most straightforward credit reductions available.
13. Install Code Intelligence Plugins for Typed Languages
This is a specific recommendation from the official Anthropic docs that I had not seen mentioned anywhere else until I read the costs page directly.
Code intelligence plugins give Claude precise symbol navigation, go-to-definition, find-references, type information, instead of text-based search. A single "go-to-definition" call replaces what would otherwise be a grep followed by reading multiple candidate files. A language server that reports type errors after each edit means Claude catches mistakes without running a full compiler check.
On a TypeScript or Go project, installing the relevant code intelligence plugin can noticeably reduce the number of exploratory file reads Claude makes per task. It does not change what Claude does, it changes how efficiently Claude finds what it needs.
Frequently Asked Questions (FAQs)
Why do my Claude credits disappear so fast with Claude Code?
The main cause is context accumulation. Every message in a long session forces Claude to re-read the entire conversation history, which means a 50-turn session costs far more per message than a 5-turn session. The second biggest cause is unused MCP servers, each active server adds thousands of tokens to every session startup. Start sessions fresh with /clear between tasks and disable MCP servers you are not actively using.
What is the difference between /clear and /compact in Claude Code?
/clear deletes all conversation history and starts completely fresh, only your CLAUDE.md and configuration reload. /compact keeps the session alive but replaces conversation history with a compressed summary, preserving continuity while reducing context size. Use /clear when switching to a new unrelated task. Use /compact proactively at around 60% context usage when you need to continue the same task.
Does Cowork use the same tokens as Claude Code?
Cowork is built on top of Claude Code and uses the same underlying token system. Every active plugin connection, MCP server, and skill adds to your session context. The same optimization techniques apply: keep installed plugins lean, use skills over CLAUDE.md for task-specific instructions, and start fresh sessions for unrelated work.
How much does Claude Code actually cost per developer?
According to Anthropic's official documentation, the average across enterprise deployments is around $13 per developer per active day, and $150-250 per developer per month. 90% of users stay below $30 per active day. Costs spike when developers run agent teams, use Opus for routine tasks, or let context accumulate without using /clear or /compact.
Does keeping extended thinking on always cost more?
Yes. Thinking tokens bill as output tokens, and the default budget can reach tens of thousands of tokens per request. For simple tasks, formatting, quick edits, generating boilerplate,extended thinking adds cost without adding value. Use /effort low or set MAX_THINKING_TOKENS=8000 in your environment for sessions focused on routine work. Reserve full thinking budgets for genuinely complex architectural or reasoning tasks.
Can I save credits by using hooks in Claude Code?
Yes, significantly. Hooks preprocess data before Claude reads it, which means you can filter verbose output down to only what Claude needs. The best example is test output filtering: a hook that shows only failing tests instead of the full test run can reduce test-related tokens from thousands to under 100. Any hook that reduces the size of what Claude actually processes has a direct credit impact.
Final Thoughts
I went from burning through my Claude credits in two days to comfortably working within my plan limits across a full month. None of the techniques above require premium tools or complex setups, they are habits and configurations that take one hour to implement and save credits indefinitely.
Start with the three highest-impact changes today: run /clear between every unrelated task, keep your CLAUDE.md under 200 lines, and disable any MCP servers you are not actively using this week. Those three habits alone will cut most users' token consumption by 30-40%. Build the rest from there.