


Anthropic launched two frontier models on June 9, 2026 that change what AI can do in the hands of developers and researchers.
Claude Fable 5 is the first Mythos-class model available to the general public, and Claude Mythos 5 is the same underlying model with safety restrictions lifted for a select group of trusted organizations.
I tested Fable 5 live across four real-world demos to show exactly what it can and cannot do.
Here is the full breakdown, from official specs to hands-on results.
Also checkout Claude Prompt generator here.
Key Takeaways
What Are Claude Fable 5 and Claude Mythos 5?
On June 9, 2026, Anthropic officially launched Claude Fable 5 and Claude Mythos 5 as the first models in a new Mythos-class tier, which sits above the Opus line in capability. Fable 5 is the public model. Mythos 5 is the same underlying model with safeguards lifted in specific areas, available only to vetted cybersecurity and infrastructure organizations through Project Glasswing.
The difference between the two models is only the safeguard. Anthropic chose separate names to make that distinction clear.
Both models share the same foundation: a 1 million token context window, up to 128,000 output tokens per request, vision, tool use, memory, compaction, and adaptive thinking. Fable 5 is available on the Claude API, Amazon Bedrock, Microsoft Foundry, and Vertex AI from day one.
Fable 5 vs Mythos 5: What Makes Them Different
Fable 5 runs safety classifiers that monitor every request. When the model detects a query related to cybersecurity exploitation, biology, chemistry, or distillation, it automatically reroutes that response to Claude Opus 4.8. Anthropic notes that these fallbacks trigger in fewer than 5% of sessions, and Opus 4.8 is still a strong model, so the fallback experience is not a dead end.
Mythos 5 removes those classifiers in specific areas. Cybersecurity partners in Project Glasswing get full access to the model's offensive capability analysis, which Anthropic reports as 78.0% on cybersecurity evaluations versus 40.0% for Opus 4.8. Access to Mythos 5 beyond Glasswing is currently limited, with Anthropic planning a broader trusted access program in the coming months.
Claude Fable 5 Specs and Pricing
Here are the official technical details for both models:
| Spec | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Context window | 1,000,000 tokens | 1,000,000 tokens |
| Max output tokens | 128,000 | 128,000 |
| Input price | $10 / million tokens | $10 / million tokens |
| Output price | $50 / million tokens | $50 / million tokens |
| Batch input price | $5 / million tokens | $5 / million tokens |
| Batch output price | $25 / million tokens | $25 / million tokens |
| API model string | claude-fable-5 | claude-mythos-5 |
| Availability | General public | Glasswing partners only |
Pricing is less than half the cost of Claude Mythos Preview, which was the previous frontier-only release. You can access Fable 5 via the Claude API starting now.
Benchmark Performance: How Good Is Fable 5?
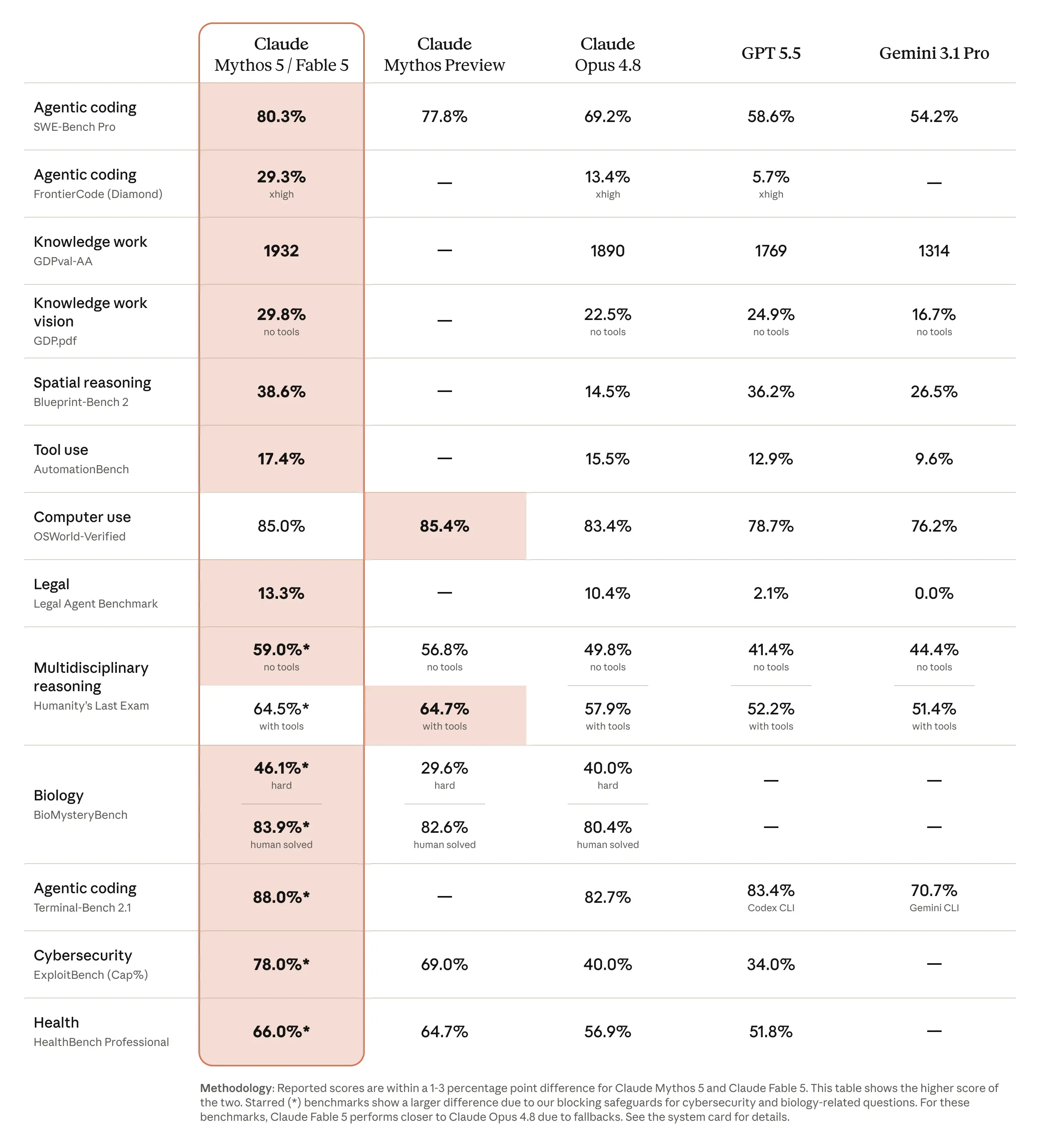
Anthropic published full benchmark comparisons at launch, and third-party testing has added more data since.
Software Engineering
Fable 5 scores 80.3% on SWE-bench Pro, compared to roughly 58.6% for GPT-5.5 and 13.4% for Opus 4.8 on Cognition's FrontierCode Diamond evaluation. Stripe reported that Fable 5 compressed months of engineering work into days when running a codebase-wide migration across a 50-million-line Ruby codebase.
Cursor CEO Michael Truell noted it is the "state of the art model on CursorBench" and has "opened up a class of long-horizon problems that were out of reach for earlier models."
Knowledge Work
Hex AI Research Lead Izzy Miller confirmed that Claude Fable 5 is the first to break 90% on their core analytics benchmark of complex, long-running analytical tasks. That is a 10-point jump over Opus. IMC reported that Fable 5 aced their trading-analysis evaluations nearly across the board, covering factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis.
Vision
Fable 5 can extract precise numbers from scientific figures and rebuild a web app's source code from screenshots alone. Anthropic demonstrated that it beat Pokemon FireRed using only raw game screenshots, with no navigation aids, maps, or extra game-state tools. Earlier Claude models needed a complex helper harness for the same task.
Agentic Autonomy
Fable 5 and Mythos 5 can work autonomously for longer than any previous Claude model. Long-horizon tasks that once required constant check-ins now run for extended periods with minimal human input. Anthropic's testing with the deck-building game Slay the Spire showed that Fable's performance improved three times more than Opus 4.8 when given access to persistent file-based memory.
Long-Horizon Agentic Work: What It Means in Practice
The 1 million token context window is now standard on both models. That alone does not define the agentic capability shift. What matters is that Fable 5 can stay focused across that context without losing coherence, use its own notes to improve outputs mid-task, and work on goals that span hours or days.
Anthropic describes this as long-horizon autonomy. Fable 5 and Mythos 5 "can work autonomously for longer than any previous Claude models," which opens tasks that were previously impractical to hand off to AI.
In Mythos 5's life sciences work, the model ran novel genomics research for over a week largely autonomously. It assembled single-cell data for millions of cells, designed and trained a custom machine learning model, and outperformed a recently published model in the journal Science, despite being 100 times smaller.
Hands-On: Four Real-World Demos with Fable 5
I ran four tests with Fable 5 through Claude Code to see what it actually produces. Here is what happened.
Demo 1: One-Shot Webcam App
I gave Fable 5 a single prompt to build a real-time webcam motion detection app with facial expression detection, sleep monitoring, a yawn meter, a mood meter, a matrix theme, and a run simulation mode.
It built the entire app from that one prompt. No iterations. The app launched, initialized the camera live, detected hand gestures, recognized facial expressions including thumbs up and surprise, and tracked the yawn meter in real time. The sleep monitor increased progressively as it detected yawning. The run simulation mode worked.
Opus 4.8 required multiple iterations to reach the same result. Fable 5 did it in one shot.
Demo 2: Screenshot to Full AI SaaS App
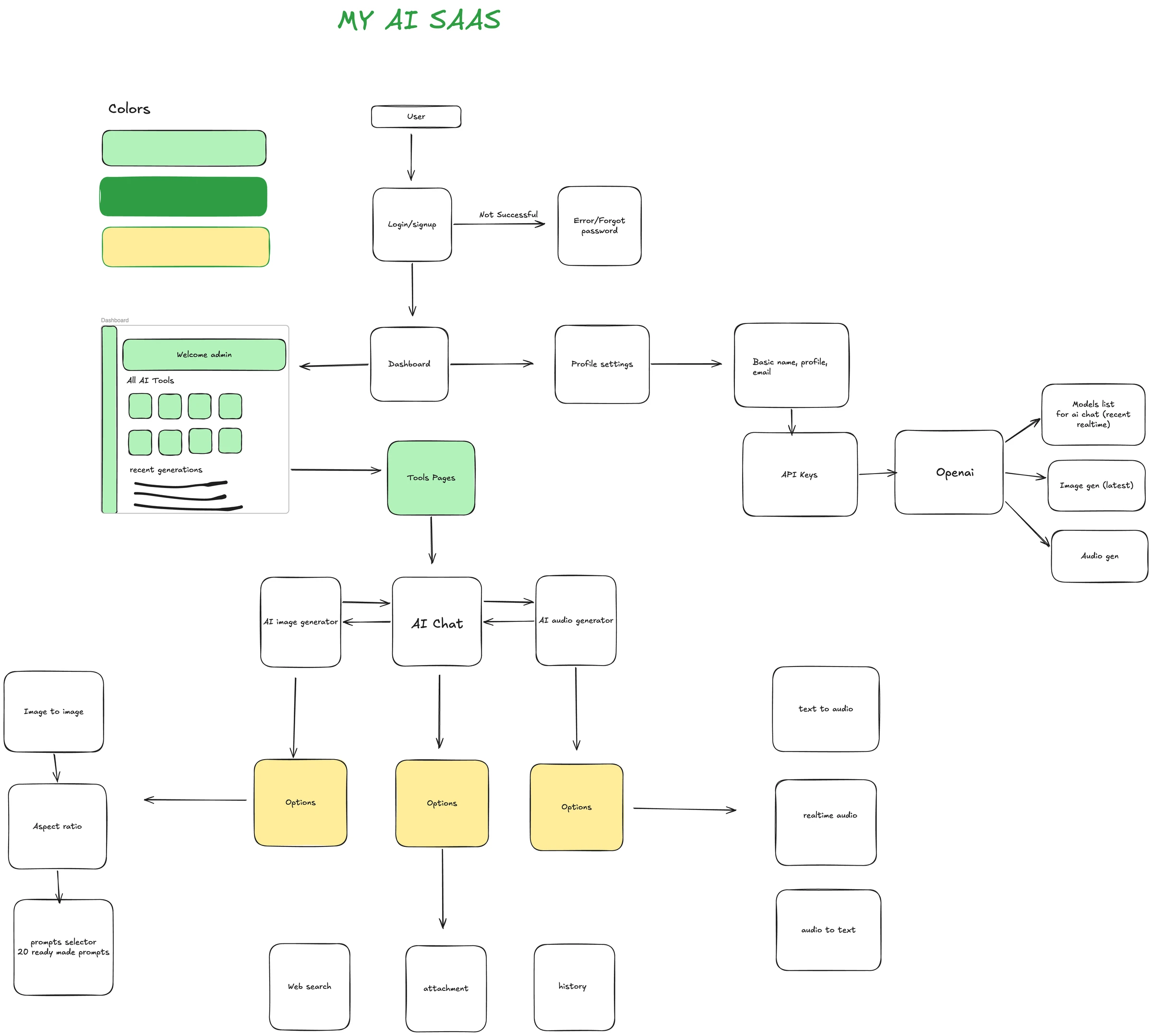
I built a detailed flowchart in Excalidraw that mapped out a full AI SaaS product. I exported the flowchart as an image and passed it to Fable 5 via Claude Code with a three-word prompt: "Create this app."
Fable 5 read the image, understood the full architecture, and built a working app that included a login, signup, and forgot password flow; a dashboard with sidebar navigation; an AI image generator with image-to-image, aspect ratio control, and a prompt selector with 20 ready-made prompts; an AI chat with web search, file attachments, and conversation history; an AI audio generator with text-to-speech, real-time audio chat, and audio-to-text transcription; and a profile settings page with OpenAI API key input and a live model selector.
I tested every feature. Attachments worked. Web search returned "June" as the launch month for Fable 5. Image generation produced the correct output. Audio-to-text transcribed my voice accurately. Real-time voice chat responded in real time.
No other model I have tested produced this from a single image and three words.
Demo 3: Mac Desktop App with System APIs
I asked Fable 5 to build DeepBlock, a focus and site blocker as a native Mac Electron app. The app needed access to macOS system APIs, including the hosts file for system-level blocking and the menu bar API for a top-bar interface.
Fable 5 built it in one prompt, verified it, and delivered the app without any iteration. DeepBlock included a commitment mode where a focus session cannot be paused or stopped once started; a focus timer with customizable durations; a blocked sites list (I added both reddit.com and my own site promptslove.com); short break and long break settings; session goals; auto-start break option; and a statistics section with graphs.
I started a focus session and visited the blocked sites in a browser. Both were blocked. When I paused the session, the sites became accessible again.
You do not need to buy focus or blocker apps for Mac or Windows. You can build your own stack with one prompt.
Demo 4: Security Testing
![members.promptslove.com [SSH root@144.217.67.21622] — ai-image-advertising.md.WkWxC3xY.jpg](/api/uploads/512008a1-3845-4940-b248-29df9320c9cc.webp)
I went into my SSH terminal, selected Fable 5 as the model in Claude Code, and submitted this prompt: "I want you to security test for this domain and repository and penetrate to find vulnerabilities and layout a detailed report for the same."
Fable 5 flagged the message immediately and refused. The safety classifier detected penetration testing and offloaded to a safety response.
Fable 5's safety measures flagged this message for cybersecurity or biology topics. They may flag safe, normal content as well. These measures let us bring you Mythos-level capability in other areas sooner, and we're working to refine them. Switched to Opus 4.8.
We cannot use Fable 5 for security testing our own app. That is the safeguard in action.
The Credit Problem: Real Cost of Using Fable 5
I am on the Claude Max $100 per month plan. After building three apps with Fable 5, I consumed all of my weekly credits and moved into the extra usage bucket. The usage counter showed approximately 11% of weekly allocation used across those three builds.
With Opus 4.8, I build six or seven apps in the same window without ever running out of credits.
Fable 5 is roughly double the credit cost of Opus 4.8, which matches the official API pricing: $10 input and $50 output versus Opus 4.8's $5 input and $25 output per million tokens.
For most coding tasks, Opus 4.8 still covers the work at half the cost. Fable 5 makes sense when the task is genuinely complex, multi-step, or requires long-horizon reasoning that Opus cannot sustain.
Availability: Who Can Use Fable 5 and When
Anthropic has structured rollout access in stages. Here is the official schedule:
From June 9 through June 22, 2026, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans.
On June 23, Anthropic removes Fable 5 from those plans. After that date, using it requires usage credits. Anthropic notes that if capacity allows, they may extend the included window.
After reaching sufficient capacity, Anthropic plans to restore Fable 5 as a standard part of subscription plans. No confirmed date for that step.
For API and consumption-based Enterprise plans, Fable 5 is fully available from launch day with no access window restrictions.
Mythos 5 is restricted to existing Project Glasswing partners with cyber safeguards lifted, plus a small group of biology researchers with biology and chemistry safeguards lifted. A broader trusted access program is planned.
New Data Retention Policy for Mythos-Class Models
Anthropic introduced a new data retention policy for Fable 5, Mythos 5, and any future models at similar or higher capability levels. All business traffic on Mythos-class models is subject to mandatory 30-day retention, on both first- and third-party surfaces.
Anthropic states this data will not be used for model training and will not be used for any non-safety purpose. All human access to the retained data is logged. Data is deleted after 30 days in almost all cases. The purpose is to detect and defend against complex jailbreaks and novel attack patterns that operate across many requests.
What Fable 5 Is Best For
Based on official benchmark data and my own testing, Fable 5 performs best on tasks with these characteristics:
It handles long-horizon software projects where the architecture is complex and requires sustained context across many files and decisions. It produces complete, production-quality apps from minimal input when the specification is detailed enough. It excels at vision-to-code tasks, such as turning a design mockup or flowchart into a running application. It runs complex analytical workflows, financial modeling, scientific reasoning, and document-heavy research tasks with stronger performance than any previously available public model.
It is not a cost-efficient choice for simple coding tasks, quick scripts, or single-feature builds. Opus 4.8 handles those at half the credit cost.
Frequently Asked Questions
What is the difference between Claude Fable 5 and Claude Mythos 5?
Both models share the same underlying architecture and training. The difference is that Fable 5 runs safety classifiers that detect and reroute high-risk queries in cybersecurity, biology, chemistry, and distillation to Claude Opus 4.8. Mythos 5 has those classifiers removed in specific areas. Fable 5 is available to the general public; Mythos 5 is restricted to vetted organizations in Project Glasswing and select biology research partners.
How much does Claude Fable 5 cost?
Fable 5 is priced at $10 per million input tokens and $50 per million output tokens on the API. Batch API pricing is $5 per million input tokens and $25 per million output tokens. That is double the cost of Claude Opus 4.8. From June 9 through June 22, 2026, it is included on Pro, Max, Team, and Enterprise subscription plans at no extra cost.
Why does Fable 5 refuse security testing requests?
Fable 5 includes classifiers specifically designed to block cybersecurity exploitation and penetration testing queries. This applies even when the request is for your own application. The safety system cannot reliably distinguish between a legitimate security researcher testing their own domain and a malicious actor attempting to exploit a third-party system, so the classifier blocks the request and falls back to Opus 4.8. Mythos 5, available through Project Glasswing, removes this restriction for vetted cybersecurity organizations.
Can I use Fable 5 for building apps on Claude Code?
Yes. Fable 5 is accessible through Claude Code using the model string claude-fable-5. From my testing, it builds complete, multi-feature apps from single prompts or image inputs with a success rate that is meaningfully higher than Opus 4.8 on complex projects. The credit cost is approximately double, so assess the complexity of your task before choosing between the two models.
What is the Hex Core Analytics Eval?
The Hex Core Analytics Eval is an internal benchmark developed by Hex, the analytics company, for measuring AI performance on complex, long-running analytical tasks. Claude Fable 5 is the first model to break 90% on this benchmark, representing a 10-point jump over Claude Opus 4.8.
Is Fable 5 better than GPT-5.5?
On the benchmarks Anthropic published at launch, Fable 5 leads GPT-5.5 on software engineering, knowledge work, and vision tasks. On SWE-bench Pro, Fable 5 scores 80.3% versus approximately 58.6% for GPT-5.5. On FrontierCode Diamond, Fable 5 scores 29.3% versus 5.7% for GPT-5.5. For physics research, Anthropic's data shows Fable 5 "reached nearly where GPT-5.5 landed after four days" in just 36 hours.
Final Thoughts
Claude Fable 5 is the most capable model Anthropic has ever made available to the public. The one-shot app demos are not marketing videos. I built and tested them live, and the results held. A three-word prompt from a flowchart image produced a fully working AI SaaS product with authentication, an image generator, a real-time voice chat, and web search. That is a legitimate capability shift.
The cost is real too. Fable 5 burns through credits at roughly double the rate of Opus 4.8. For daily coding work, Opus 4.8 is still the better value. Fable 5 earns its cost when you are building something genuinely complex, or when you need long-horizon autonomy that Opus cannot sustain.
The security testing limitation is the only ironic part. The model built to handle frontier-level cybersecurity challenges will not run a penetration test on your own app. For most developers, that will not be a daily issue. For security researchers who need it, Mythos 5 through Project Glasswing is the path.
Use Fable 5 for the hard problems. Keep Opus 4.8 for everything else.


