


I did not expect this.
I run Claude Opus 4.8 as my go-to coding model. It has handled everything I threw at it - SaaS apps, games, Mac utilities, Python scripts. But last week, I decided to run a proper side-by-side test against GLM 5.2, Zhipu AI's brand new open-source release that just dropped on June 13, 2026. The plan was simple: five identical prompts, both models, same environment via OpenCode on OpenRouter, no favoritism.
By the end of test three, I was already questioning my $200/month setup. By the end of test five, I was genuinely reconsidering my Claude subscription. In this review, I walk you through every test, the exact results I saw, the full spec breakdown for both models, and my honest verdict on which one belongs in your coding workflow.
Checkout our Free GLM Prompt generator here.
Key Takeaways
GLM 5.2 Specs: What Zhipu AI Built
Before I get into the test results, here is what you need to know about GLM 5.2.
Zhipu AI - also known as Z.ai - shipped GLM 5.2 on June 13, 2026. The model uses a Mixture-of-Experts architecture with 744 billion total parameters, but only 40 billion activate per token. That design keeps inference costs low while maintaining frontier-level reasoning capacity.
Context Window and Output Limits
GLM 5.2 comes with a 1,048,576-token context window. In plain language, that is about 750,000 words of input at once. You can paste an entire mid-sized codebase, a full set of API documentation, and a project spec and ask the model to reason over all of it in one shot.
The maximum output per response is 262,144 tokens - more than double Claude Opus 4.8's 128k cap. For long codebases or detailed multi-file outputs, that matters.
Reasoning Modes
GLM 5.2 ships with two selectable reasoning modes. High mode is fast and handles everyday code, summaries, and tasks where answers are straightforward. Max mode runs slower and more deliberate - it spends extra compute reasoning before it responds. Expect 30 to 80 percent higher latency in Max mode, but you get noticeably better results on complex multi-file coding and long agentic workflows.
Pricing
This is where GLM 5.2 separates itself:
Compare that to Claude Opus 4.8 at $5/M input and $25/M output. On output tokens specifically - which dominate the bill in agentic coding sessions - GLM 5.2 runs 5.7x cheaper. A workload costing $1,000 per day on Opus 4.8 output would cost around $176 per day on GLM 5.2.
License and Availability
GLM 5.2 ships under an MIT license. The open weights are on HuggingFace. You can run it on vLLM, SGLang, xLLM, KTransformers, and standard Transformers. No regional restrictions. No API gate. You can fine-tune it, quantize it, run it completely air-gapped, and pin a version forever. For teams in privacy-sensitive environments or enterprise setups that need control over their stack, this is a massive deal.
Benchmark Performance
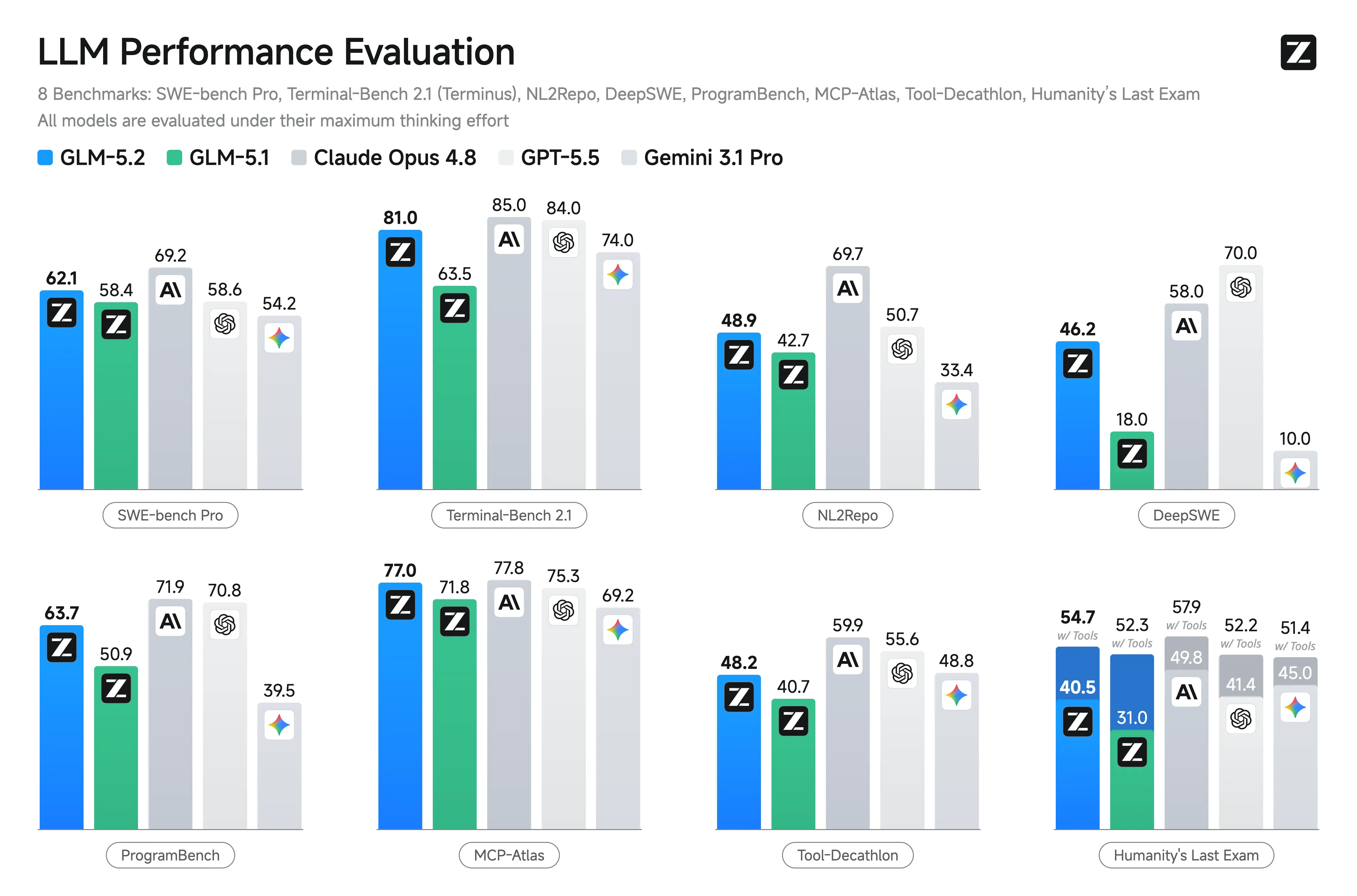
Zhipu did not publish a full official benchmark table at launch. But third-party results are already in. GLM 5.2 scores 81.0 on Terminal-Bench 2.1 and 62.1 on SWE-bench Pro. On FrontierSWE and MCP Atlas - two of the most important agentic benchmarks - GLM 5.2 sits within 0.7 and 0.8 points of Claude Opus 4.8. No open-weight model has ever gotten this close to the proprietary leader on those two benchmarks.
Claude Opus 4.8 Specs: Anthropic's Current Flagship
Claude Opus 4.8 launched on May 28, 2026. It carries the model ID claude-opus-4-8 and is Anthropic's current top coding model.
Context Window and Output Limits
Claude Opus 4.8 has a 1 million token context window enabled by default and a 128k maximum output token cap. For most everyday tasks, 128k output is more than enough. But for projects that require extremely long generated files or multi-file scaffolding in one pass, that ceiling matters.
Pricing
Fast mode is useful for iteration speed during development, but at that price point it becomes one of the most expensive models available via API.
Key Features
Anthropic reports Claude Opus 4.8 is around four times less likely than its predecessor to let flaws in generated code pass unremarked. It scored 84% on Online-Mind2Web - a strong result for web navigation tasks. It also became the first model to break 10% on the Legal Agent Benchmark all-pass standard, which tests long-horizon legal reasoning.
Opus 4.8 includes adaptive thinking, mid-conversation system messages without a beta header, and supports Claude Code Workflows as a research preview.
Availability
Claude Opus 4.8 is closed-source, proprietary, and API-only. You cannot self-host it or run it offline. All traffic goes through Anthropic's infrastructure.
The Test Setup: How I Ran These Comparisons
I ran both models through OpenCode using OpenRouter as the API layer. OpenRouter lets you swap between models by changing one line of configuration, which made it easy to run identical prompts against each without context bleeding or session carryover.
For each test, I gave both models the same prompt in a clean session and compared the result on first attempt. No retries, no extra prompting - just one shot each, the way most developers actually work.
Test 1: Cascade UI - Multi-Page HTML/CSS with Animations
The first test was a multi-page Cascade UI with smooth animations and a dark/light mode toggle.
Claude Opus 4.8: Built a solid multi-page layout. The animations looked clean. But the dark/light mode toggle had a clear glitch - elements were not switching properly between themes.
GLM 5.2: Delivered noticeably better 3D animations. The visual depth felt more polished. It also had minor issues, but the overall result looked more impressive on screen.
Verdict: Tie. Both models had issues. GLM 5.2 had the better visual output, but neither fully nailed the dark/light mode behavior on the first pass.
Test 2: SaaS App - GitHub Clone
Next up was a full SaaS GitHub clone app. My prompt specifically asked for a landing page as part of the build.
Claude Opus 4.8: Built the core GitHub clone functionality. Skipped the landing page entirely despite it being in the prompt.
GLM 5.2: Built the GitHub clone AND added the landing page exactly as requested. It followed the full instruction without needing a reminder.
Verdict: GLM 5.2 wins. This is a practical difference that matters in real workflow. If your prompt has multiple requirements and the model drops one of them, you lose time. GLM 5.2 read the prompt correctly and executed on all of it.
Test 3: Tower Defense Game
This one went to Anthropic's model.
The prompt was for a complete tower defense game with a proper UI, including a fort gate and game mechanics.
Claude Opus 4.8: Produced a polished game UI. The fort gate was properly built into the scene. The mechanics worked and the layout was clean.
GLM 5.2: The UI came out stacked awkwardly. The fort gate element was missing. Visually it looked incomplete compared to Opus 4.8's version.
Verdict: Claude Opus 4.8 wins. This was the one test where Opus 4.8 clearly outperformed. For game UI and structured visual layout, it was the stronger result on this prompt.
Test 4: Mac Desktop App - Snippet Capture Utility
This test is where things got uncomfortable for Claude Opus 4.8.
The prompt was to build a Mac desktop app - a snippet capture utility with demo data, a working keyboard shortcut (Command+Shift+S), and a settings panel with a color picker.
Claude Opus 4.8: Launched a blank window. Nothing worked. No demo data appeared. The keyboard shortcut was not implemented. The settings panel was empty. I described it as "very disappointing" and it genuinely was - this is exactly the kind of native app task where I had always relied on Opus.
GLM 5.2: Built a working interface. Demo data loaded on launch. Command+Shift+S fired the snippet capture. The settings panel included a functional color picker. On the first pass, it delivered a usable app.
Verdict: GLM 5.2 wins decisively. This was the most striking result in the entire test. The gap here was not close.
Test 5: Repolens - Python Codebase Analyzer with Charts
The fifth and final test was a Python-based app I am calling Repolens - a tool that analyzes a local code repository and generates visual charts: a language distribution chart, a tree map, and a complexity chart.
Claude Opus 4.8: Launched a blank screen. Nothing loaded when I told it to start the app. There was no interface, no charts, no output at all.
GLM 5.2: Launched a proper interface on the first attempt. The left panel showed all the repository files. The right panel displayed three charts: the language distribution chart, the tree map, and the complexity chart. When I loaded a local repository and clicked Analyze, all three charts populated correctly. The OpenRouter API key input even included a working "Test Connection" button.
The AI analysis feature inside the app still needs work - it was not functional during the test - but the core app was genuinely usable from the first run.
Verdict: GLM 5.2 wins. Another blank result from Opus 4.8 versus a fully functional interface from GLM 5.2.
Overall Test Scorecard
| Test | Claude Opus 4.8 | GLM 5.2 | Winner |
|---|---|---|---|
| Cascade UI (multi-page HTML/CSS) | Minor dark/light glitch | Better 3D animations, minor issues | Tie |
| SaaS App (GitHub clone) | Skipped landing page | Full build + landing page | GLM 5.2 |
| Tower Defense Game | Polished UI, fort gate included | Stacked UI, missing gate | Claude Opus 4.8 |
| Mac Desktop App (snippet capture) | Blank app, nothing worked | Working UI, shortcut, color picker | GLM 5.2 |
| Python Codebase Analyzer (Repolens) | Blank screen, no output | Full interface, 3 charts, file panel | GLM 5.2 |
Final score: GLM 5.2 wins 3 tests, Claude Opus 4.8 wins 1 test, 1 tie.
Head-to-Head Spec Comparison
| Spec | GLM 5.2 | Claude Opus 4.8 |
|---|---|---|
| Developer | Zhipu AI (Z.ai) | Anthropic |
| Release Date | June 13, 2026 | May 28, 2026 |
| Architecture | 744B MoE (40B active) | Closed / undisclosed |
| Context Window | 1,048,576 tokens | 1,000,000 tokens |
| Max Output Tokens | 262,144 | 128,000 |
| Input Price | $1.40/M tokens | $5.00/M tokens |
| Output Price | $4.40/M tokens | $25.00/M tokens |
| License | MIT (open weights) | Proprietary |
| Self-Hostable | Yes | No |
| Reasoning Modes | High / Max | Adaptive thinking |
| Available on OpenRouter | Yes | Yes |
Benchmark Comparison: Where Each Model Leads
On formal benchmarks, Claude Opus 4.8 still leads in long-horizon software engineering tasks. Its widest advantages show up on NL2Repo (69.7 vs 48.9 for GLM 5.2), SWE-Marathon (26.0 vs 13.0), and Tool-Decathlon (59.9 vs 48.2).
But the story on newer benchmarks is very different. On FrontierSWE, GLM 5.2 is within 0.7 points of Claude Opus 4.8. On MCP Atlas, the gap is 0.8 points. GLM 5.2 also scores 81.0 on Terminal-Bench 2.1 - a benchmark measuring CLI and agentic task performance.
VentureBeat reported that GLM 5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks at one-sixth the cost. For a model released this week, that is a significant result.
How to Access GLM 5.2 Right Now
The fastest way to use GLM 5.2 today is through OpenRouter. Here is what you do:
z-ai/glm-5.2 as your modelI ran all five tests this way. The integration with OpenCode was seamless. GLM 5.2 responded as fast as Opus 4.8 in most cases.
The open weights version is scheduled to land on HuggingFace the week of June 22, 2026. Once that is live, you will be able to run it locally on vLLM, SGLang, or any compatible inference stack.
Who Should Use GLM 5.2 vs Claude Opus 4.8
Use GLM 5.2 if:
Use Claude Opus 4.8 if:
Frequently Asked Questions (FAQs)
Is GLM 5.2 actually open source?
Yes. GLM 5.2 ships under an MIT license with fully open weights on HuggingFace. You can download it, fine-tune it, quantize it, and run it completely offline. There are no regional restrictions and no API gate required. This makes GLM 5.2 one of the most permissively licensed frontier models available today.
How much cheaper is GLM 5.2 compared to Claude Opus 4.8?
On input tokens, GLM 5.2 is 3.6x cheaper ($1.40 vs $5.00 per million tokens). On output tokens - which drive most of the cost in agentic sessions - GLM 5.2 is 5.7x cheaper ($4.40 vs $25.00 per million tokens). In practice, most developers save around 80% on their monthly API bill when switching from Opus 4.8 to GLM 5.2 for the same workload.
Can I use GLM 5.2 with OpenCode and Claude Code?
Yes. GLM 5.2 is available on OpenRouter, and OpenCode supports OpenRouter as a model provider out of the box. You change the model selection to z-ai/glm-5.2 and your existing OpenRouter API key handles the rest. The workflow I used in all five tests ran exactly this way.
Does GLM 5.2 support a 1 million token context window?
Yes. GLM 5.2 has a context window of 1,048,576 tokens - usable in practice, not just on paper. That is about 750,000 words of input at once. You can load an entire mid-sized codebase plus full API documentation and reason over all of it in a single prompt. The maximum output per response is 262,144 tokens, which is more than double Claude Opus 4.8's 128k limit.
Did Claude Opus 4.8 really lose to a new open-source model?
In my direct test of 5 real-world coding projects, yes. GLM 5.2 won 3 tests, Claude Opus 4.8 won 1, and 1 was a tie. The most striking result was the Mac desktop app test, where Opus 4.8 produced a completely blank and non-functional result while GLM 5.2 delivered a working app with demo data, keyboard shortcuts, and a color picker on the first pass. On formal long-horizon benchmarks, Claude Opus 4.8 still leads - but the gap is narrowing fast.
What is the difference between GLM 5.2's High and Max reasoning modes?
High mode is fast and handles straightforward coding tasks, summaries, and everyday generation. Max mode is slower and more deliberate - the model does more internal reasoning before it responds. Expect 30 to 80 percent higher latency in Max mode, but you get significantly stronger results on complex multi-file projects, long agentic chains, and difficult coding challenges that need careful step-by-step planning.
Final Thoughts
I started this comparison expecting Claude Opus 4.8 to win. It is the model I pay for every month. It has never failed me on production work. But the results I got were clear: GLM 5.2 outperformed Opus 4.8 in three out of five live coding tests, costs 80% less, and ships with MIT open weights you can run anywhere.
That does not mean Opus 4.8 is dead. On long-horizon software engineering benchmarks like NL2Repo and SWE-Marathon, Claude Opus 4.8 still holds a real lead. If you need those capabilities, the premium is justifiable.
But for most developers running practical coding projects - SaaS apps, desktop tools, Python scripts, UI builds - GLM 5.2 is producing better results at a fraction of the price. Zhipu AI just released a model that puts serious pressure on the best closed-source options out there.
I am reconsidering my Claude Code subscription. You should at least test GLM 5.2 before renewing yours.
Try GLM 5.2 now at openrouter.ai/z-ai/glm-5.2. The open weights land on HuggingFace the week of June 22, 2026.


